
ISSN (0970-2083)
ISSN (0970-2083)
1Faculty of Electronics Technology, Industrial University of Ho Chi Minh City, 12 Nguyen Van Bao Street, Ho Chi Minh City, Viet Nam
2Optoelectronics Research Group, Faculty of Electrical and Electronics Engineering, Ton Duc Thang University, Ho Chi Minh City, Vietnam
Received Date: 07 August, 2017; Accepted Date: 20 September, 2017
Visit for more related articles at Journal of Industrial Pollution Control
Moving object is detected by simple spatial and temporal gradients in GOP (Group of Frame) of H.264/AVC such that the MOOI (Moving-Object-of-Interest) is remained as much as possible while the non-MOOI is squeezed. This resizing process to original video is applied as a pre-processing for standard video compression. Specifically, more image data of the original video will be dropped by our non-uniform subsampling as the distance from the center of the MOOI increases. Experimental results show that our MOOI aware video compression can preserve the original visual quality of the MOOI even for low bit-rate applications.
https://myseoblog.blogdon.net/
https://myseoblog.blogaaja.fi/
https://myseoblog.jimdosite.com/
https://myseoblog.edublogs.org/
https://myseoblog.websites.co.in/
https://myseoblog47.wordpress.com/
https://myseoblog.waarnnnnnnbenjij.nu/
https://myseoblog.jigsy.com/
https://szeith-rhounds-kliagy.yolasite.com/
https://myseoblog-40.webselfsite.net/
https://myseoblog.mystrikingly.com/
https://myseoblog.splashthat.com/
https://myseoblog.webnode.com.tr/
https://myseoblog.odoo.com/
https://myseoblog.creatorlink.net/
https://whiteseotr1-s-site.thinkific.com/
https://myseoblog.estranky.cz/
https://65390c7d9a166.site123.me/
https://myblogseoooo.blogspot.com/
https://myseoblog.hashnode.dev/
https://whiteseotr1.wixsite.com/myseoblog
https://myseoblogg.weebly.com/
https://sites.google.com/view/myseoblogg/
https://codepen.io/myseoblog/pens/public
https://myseoblogg.livejournal.com/
https://wakelet.com/@myseoblog87204
https://www.homify.com/users/9537482/myseoblog/
https://theomnibuzz.com/author/myseoblog/
https://lessons.drawspace.com/profile/323508/myseoblog/
https://my.desktopnexus.com/myseoblog/
https://writeupcafe.com/profile/myseoblog/
https://www.pearltrees.com/myseoblog
https://www.easyfie.com/myseoblog
https://pharmahub.org/members/27544
https://www.zupyak.com/u/myseoblog/posts
https://www.metroflog.co/myseoblog
https://www.fuzia.com/fz/myseoblog-myseoblog
https://tr.pinterest.com/whiteseotr1/
https://my.getjealous.com/myseoblog
https://micro.blog/myseoblog
https://www.tumblr.com/blog/myseobloggsblog
https://hub.docker.com/u/myseoblog
https://fire.blogfree.net/?act=Profile&MID=1342100
https://myseoblog.pixnet.net/blog
https://myseoblogg.seesaa.net/
https://www.threadless.com/@myseoblog/activity
https://neocities.org/site/myseoblog
https://myseoblog.amebaownd.com/
https://teletype.in/@myseoblog
https://ubl.xml.org/users/myseoblog S6t3Bh9Gwo
https://educatorpages.com/site/myseoblog/
https://myseoblog.onlc.fr/
Moving object, Video compression resizing, PSNR
Video compression plays an important role in digital video surveillance and DVR (digital video recording) systems (Venkatraman and Maku, 2009; Kim, et al., 2012). A major concern issues of the above applications is how to efficiently compress the long hours of video data with high compression ratios. That is, the problem is how to maintain high compression ratios while preserving visual quality of the important objects in the video. The senses include the static and moving objects regions. Obviously, moving objects are considered as important regions in surveillance videos. Therefore, the desired requirements are that one can separate the important MOOI (Moving- Object-of-Interest) from the unimportant non-MOOI to treat them separately for compressions. To this end, object segmentation and tracking processes can be applied (Spagnolo, et al., 2006; Kim and Hwang, 2002; Chien, et al., 2002). However, these methods need to identify accurate object boundary, which in turn requires computationally expensive segmentation and tracking processes.
Our approach for the above problem is to roughly identify the center of the MOOI and the bounding box surrounding the MOOI for each GoF (Group-of- Frame) with simple spatial and temporal gradient energies, where the bounding box of the detected MOOI is fixed for all frames in the GoF. Here, the MOOI detection is based on the representative frame of GoF in (Nguyen and Won, 2013) and it is the area of temporal and spatial saliency. Now, the areas of the MOOI and non-MOOI are identified and we apply a logarithmic nonlinear transformation of (Won and Shirani, 2011) at the center of the MOOI combining with the linear resizing of (Le, et al., 2014) to reduce the size of the image frame such that the image data within the MOOI is intact while those in the non-MOOI are reduced as much as possible. Then, the size-reduced image frames undergo the standard H.264/AVC compression for further compressions. At the receiver, the compressed bitstream is first applied to H.264/AVC decompression to reconstruct the size-reduced video and then the invertible logarithmic transformation and an interpolation scheme are applied to restore the video data with the original image size. Note that image pruning scheme with image down-sampling as a preprocessing step of video compressions has been also proposed in (Vo, et al., 2010), where one of the two consecutive image lines (i.e., even or odd lines) is to be dropped for image size reduction. Since the line dropping is limited for one of two consecutive lines and the criterion for line dropping is based on the LMSE (Least Mean Square Errors) of the interpolated image data, it is hard to treat the MOOI and the non- MOOI separately.
Detecting moving object by motion vector is the burden process. To simplify, MOOI is detected by using spatial and temporal gradients in each GoF of H.264 to prevent artifact in temporal domain. A spatial gradient map Stg(i,j) of even frame It size Nr x Nc of a GOF kth including N0 frames from frame m0 (suppose is even number) is a sum of spatial gradients within a window 2Ψ+1 as (1)
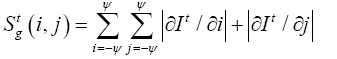 (1)
(1)
We can compute the temporal saliency cost n ( , ) t S i j in (2) as temporal gradient changes between spatial gradient maps of two executive even frames:
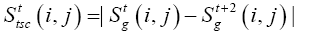 (2)
(2)
Different from [6] which proposed gray level representative frame, in our paper a temporal gradient representative frame TRFGoF of all even frames of a kth GoF is defined as (3)
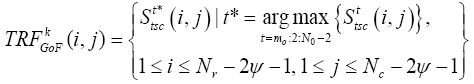 (3)
(3)
Because motion pixel (i, j) will present higher 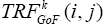 value than non-motion pixel, the MOOI of our proposed method is the window (2wr+1) (2wc+1) where sum of
value than non-motion pixel, the MOOI of our proposed method is the window (2wr+1) (2wc+1) where sum of 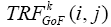 within this window yields the maximum value and center C(Cr, Cc) of MOOI is the center of this window. (Figure 1) shows the result for one moving object detection and two moving object detection. The method proposed in (Le, et al., 2014) are used determine the optimal windows size and center. By using this method, the size of window which encapsulates the moving objects can be adjust to fit the much moving areas in GOF (Figure 1).
within this window yields the maximum value and center C(Cr, Cc) of MOOI is the center of this window. (Figure 1) shows the result for one moving object detection and two moving object detection. The method proposed in (Le, et al., 2014) are used determine the optimal windows size and center. By using this method, the size of window which encapsulates the moving objects can be adjust to fit the much moving areas in GOF (Figure 1).

Figure 1: Optimal window size and reduced frame with intact MOOI. (a) optimal window for one moving object (b) optimal window for two moving objects (c) reduced frame for one moving objects (d) reduced frame for 2 moving objects. (a) Detected one moving object, (b) Detected two moving objects, (c) Frame reduction keeping one moving object, (d) Keeping 2 moving objects.
After MOOI is defined, we apply the non-uniform logarithmic transform as (Won and Shirani, 2011) to reduce original size Nr x Nc to size Mr x Mc at encoder at a predefined reduced rate. The (4) is used to reduce row size Nr → Mr then the same way to column size.
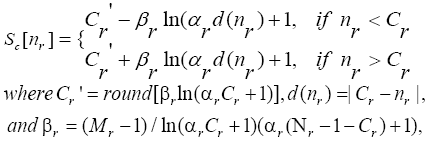 (4)
(4)
Cr C'r are row index of center of MOOI of original frame and reduced frame respectively. d(nr) is the absolute distance from Cr to pixel position nr in original frame. β converts the original size Nr to reduced size Mr. αr is responsible for the degree of expansion MOOI after row reduction. Based on the characteristic of logarithmic transform equation 4, the nearer the pixel positions to center of MOOI in original video frame, the more density of pixels in down-sampled frame grid (Figure 2).

Figure 2: Size reduction on one direction with no change within MOOI w=32.
In this paper, a method is proposed to determine row αr to make almost no reduction or expanding within MOOI after row reduction, which is illustrated as (Figure 2). The following (5) is the criterion to determine wr. The same way can be used to find column αc for wc.
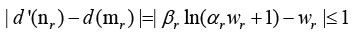 (5)
(5)
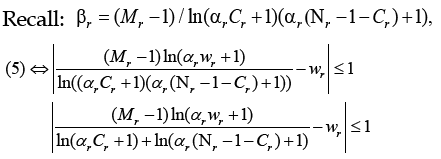
The condition in (6) is the results after appling Taylor approximation.
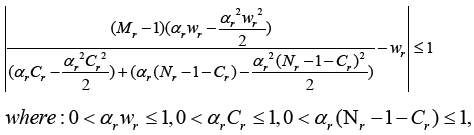 (6)
(6)
After doing mathematical expression the α will be calculated as (7)
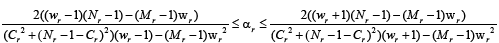 (7)
(7)
To refine estimated row alpha more accurately, an iterative method can be used with an above selected row alpha pays a role as initial row alpha. Iterative step=0.001 and Iterative times = interactive max Itmax, interactive loop will stop if condition of (5) is satisfied (Figure 3).

Figure 3: Distortion within big window using logarithmic transform, blue line is logarithmic transform and red line is linear transform. (a) Big window (b) Small window.
Finding optimal alpha by above method can assure that the pixels in reduced frame at the boundary of predefined window is kept as same as original pixels. However, in case of big windows, logarithmic transform as (7) makes the pixels within this window is distorted especially if window size is too big (Figure 3). To remove this artifact, instead of logarithmic transform, we propose a linear transform (the red line) will be used for all pixels within MOOI window if the windows is larger than predefined threshold Wm. To this end, for the big window, our transform is the combination between logarithmic transform within non-MOOI and linear transform within MOOI (Figure 4).

Figure 4: Reduction 30%. (a) Representative temporal gradient frame (b) Original (c) LMSE (d) Reduce logarithmic in window (e) Reduce linear in window.
After size reducing, conventional H.264 is used to compress reduced video at a predefined bit rate. Note that reduced frames have MOOI almost same as original frames and these size is less than original frames. This way makes ROI can be compressed by lower compression ratio at the same bit rate than original H.264. The main advantage of logarithmic transform (Won and Shirani, 2011) is that it is invertible ability to retrieve the original size after reducing. This means, at the decoder for non-MOOI region, expanding reduced size to original size is done firstly for horizontal then vertical size by an invert mapping (8). d'(mr) is the absolute distance from C'r to pixel position mr. If mr in equation (8) is non-integer in the frame grid, one interpolation operator likes bilinear can be used to find the nearest integer pixel value. Considering MOOI region, because the parameters center of MOOI and MOOI size are known as well as MOOI in reduced frame is almost same as original frame, pixels are matched one to one from reduced frame to expanded frame. Note that, the parameters  and reduction rate are sent to decoder as side information to expand reduced frame
and reduction rate are sent to decoder as side information to expand reduced frame
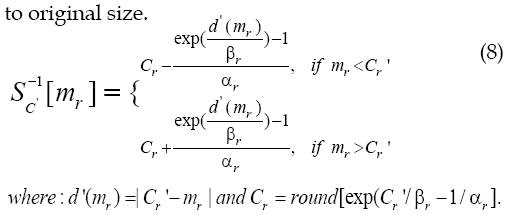
The surveillance video sequences from the (http:// ivylab kaist.ac.kr/demo/vs/dataset.htm) were used. In our experiment Wm=100. At the encoder, frames in each GOF defined by H.264 parameter are down-sampled by our method in section II and LMSE method in paper (Vo, et al., 2010) then compressed at the fix bit rate. At the decoder, they are up-sampled by bilinear interpolate. Frame reduction ratio 30% and bitrates from 50-200 kbps are tested to find the critical bitrate. Proposed method is compared with conventional H.264. (Figure 4) gives the results of difference kinds of transforms. Our proposed method (the combination of logarimic transform and linear transform) can preserve the moving object intact. Visualize results of MOOI are provided in (Figure 5) for one frame of hallway sequence. As one can see, proposed method outperforms than H.264 and LMSE in MOOI in terms of PSNR and visualize. Look at the person face that is detected as MOOI of 450th frame of Stair sequence, as the result of keeping MOOI intact after frame reduction step and using lower compression ratio at same bitrate, proposed method can be recognized more clearly despite very high compression ratio. In other hand, His face cannot be seen clearly if LMSE or conventional H.264 are used.

Figure 5: Zoom in expanded MOOI of 450th frame of Hallway sequence: 30% reduced frame bitrate 100 kbps. (a) Original (b) H.264 (c) LMSE (d) Proposed method.

Figure 6: Rate and distortion R&D for MOOI regions and whole image.
The contributions of this paper are the introductions of roughly detecting moving object of interest (MOOI) method and keeping decoded MOOI clearly in spite of high compression ratio. A preprocessing step that combines logarithmic transform and linear transform to reduce video frames resolution is proposed. The parameters alpha of logarithmic transform is optimal so that MOOI is kept intact after reducing step. Experimental results show the decoded videos yield the best results in terms of PSNR for MOOI about 3dB higher than LMSE and visualize comparison. The proposed approach is the good idea to applications where video steam should compression at high compression ration like surveillance scenes, video calls.
Copyright © 2025 Research and Reviews, All Rights Reserved